



1.概述
HDFS集群: 负责海量数据的储存,由三个部分所组成,分别为NameNode,DateNode,SecondaryNameNode.
<!--more-->
NameNode:NameNode是HDFS集群的主服务器,通常称为名称节点或者主节点。一但NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都由NameNode存储。
DateNode:DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表,每当DataNode启动时,它将负责把持有的数据块列表发送到NameNode机器中。
SecondaryNameNode:辅助NameNode,分担其工作量。比如定期合并Fsimage和Edits,并推送给NameNode,相当于NameNode的一个秘书。
2.安装要求
需要三台以上的Linux服务器,以及Java环境。(本次使用四台服务器来搭建)
3.配置静态IP
首先是先确定四台服务器的IP范围与主机名
主机 | IP |
|---|---|
NameNode | 192.168.106.128 |
SecondaryNameNode | 192.168.106.129 |
DataNode1 | 192.168.106.130 |
DataMode2 | 192.168.106.131 |
设置服务器IP:
cd /etc/sysconfig/network-scripts/&&vi ifcfg-ens33IPADDR=192.168.106.128#主机IP
PREFIX=24
GATEWAY=192.168.106.2#网关
DNS1=114.114.114.114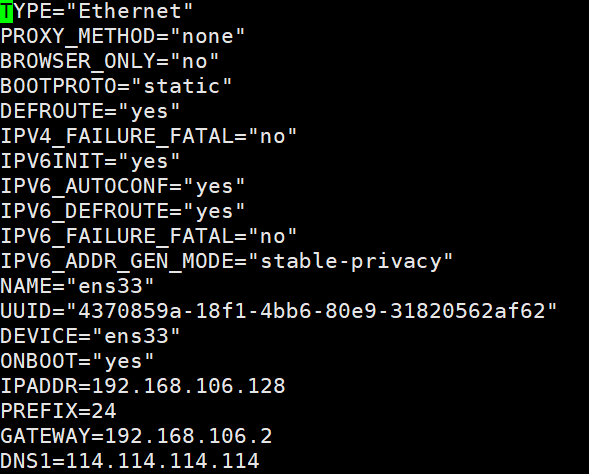
然后重启即可生效
reboot其他三台服务器也是一样的操作
4.配置Java环境
首先安装好Filezilla文件上传工具便于jdk的上传
yum install lrzsz输入rz
解压jdk
tar -xvf jdk-8u221-linux-x64.tar.gz将文件夹复制到/usr/local/下,并重命名为jdk8
cp -r jdk1.8.0_221 /usr/local/jdk8将jdk添加到系统环境变量
vi /etc/profileexport JAVA_HOME=/usr/local/jdk8
export PATH=$PATH:$JAVA_HOME/bin  立即生效
立即生效
source /etc/profile测试一下
java -version
vi Hello.javapublic class Hello{
public static void main(String[] args){
System.out.println("Hello World");
}
}javac Hello.java && java Hello出现这个说明Java环境已经配置好了

5.HDFS的搭建
上传Hadoop的压缩包到服务器
解压压缩包
tar -xvf hadoop-3.1.3.tar.gz将解压后的文件复制到/usr/loacl/下
cp -r hadoop-3.1.3 /usr/local/hadoop-3.1.3将Hadoop添加到系统变量中
vi /etc/profile将以下内容添加到Java系统变量的下面
export HADOOP_HOME=/usr/local/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin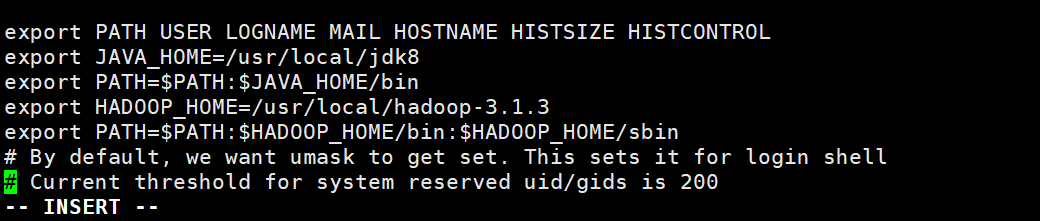
最后让系统变量生效
source /etc/profile查看Hadoop是否安装完成
hdfs version 出现以上提示则说明安装完成
出现以上提示则说明安装完成
下面接着配置hadoop-env.sh,由于通过SSH远程启动进程的时候默认不会加载/etc/profile设置,JAVA_HOME变量就加载不到,需要手动指定。
hadoop-env.sh文件在/usr/local/hadoop-3.1.3/etc/hadoop目录下
cd /usr/local/hadoop-3.1.3/etc/hadoop&&vi hadoop-env.sh然后添加jdk的路径
export JAVA_HOME=/usr/local/jdk8
配置core-site.xml
打开core-site.xml
cd /usr/local/hadoop-3.1.3/etc/hadoop&&vi core-site.xml
<configuration>
<!--用来指定hdfs的namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://NameNode:9820</value>
</property>
<!-- 指定hadoop数据的存储目录,这个目录会自动创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/root/hadoop/full</value>
</property>
</configuration>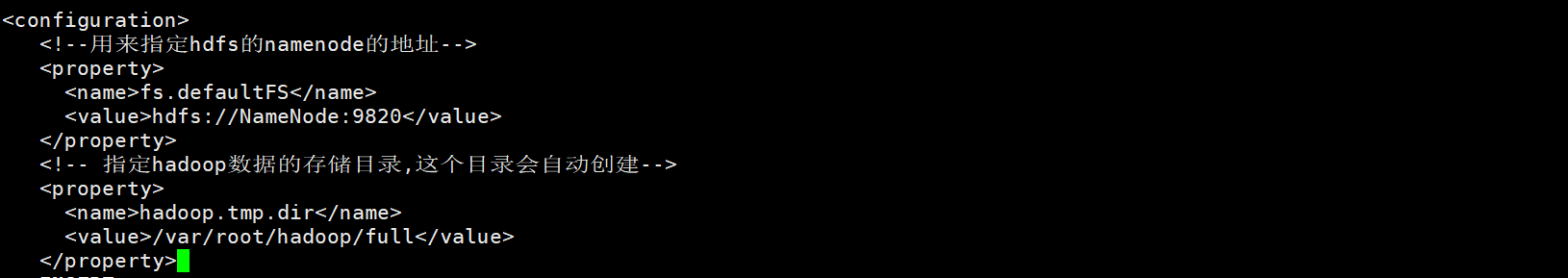
配置hdfs-site.xml
vi hdfs-site.xml<!-- 指定NameNode web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>NameNode:9870</value>
</property>
<!-- 指定secondary namenode web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SecondaryNameNode:9868</value>
</property>
<!-- 指定每个block块的副本数,默认为3 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>6.配置其他主机
关闭防火墙和禁用防火墙
systemctl stop firewalld && systemctl disable firewalld使用vm直接克隆三台服务器,然后分别配置好主机名和IP
设置四台主机的免密登录 1.生成密钥(在xshell中可以批量执行)
ssh-keygen -tdsa -P '' -f ~/.ssh/id_dsa2.将密钥拷贝到authorized_keys中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys3.然后分别将密钥拷贝到四台机器上即可
scp ~/.ssh/authorized_keys SecondaryNameNode:/root/.ssh/
scp ~/.ssh/authorized_keys DataNode1:/root/.ssh/
scp ~/.ssh/authorized_keys DataNode2:/root/.ssh/设置使用root用户登录(四台机子上都执行)
cd /usr/local/hadoop-3.1.3/sbin && vi start-dfs.sh修改主机名hostName(使用主机名来替代ip)
vi /etc/hostname集群内主机的域名映射配置
可以通过域名访问IP 在header上, vi /etc/hosts
192.168.106.128 NameNode
192.168.106.129 SecondaryNameNode
192.168.106.130 DataNode1
192.168.106.131 DataNode2#将hosts文件拷贝到集群中的所有其他机器上
scp /etc/hosts node1:/etc/
scp /etc/hosts node2:/etc/
scp /etc/hosts node3:/etc/使配置立即生效
source /etc/profileworkers**配置**
cd /usr/local/hadoop-3.1.3/etc/hadoopvi workers加入所有的节点
header
node1
node2
node37.启动hdfs
start-dfs.sh
以上用到的文件
链接:https://pan.baidu.com/s/1yocUPFD1NKg80Q6AIyvKFg
提取码:02et
评论区