



使用requests实现下载喜马拉雅音频
分析音频地址
首先任意打开一个专辑

然后按f12打开开发者工具,找到Network
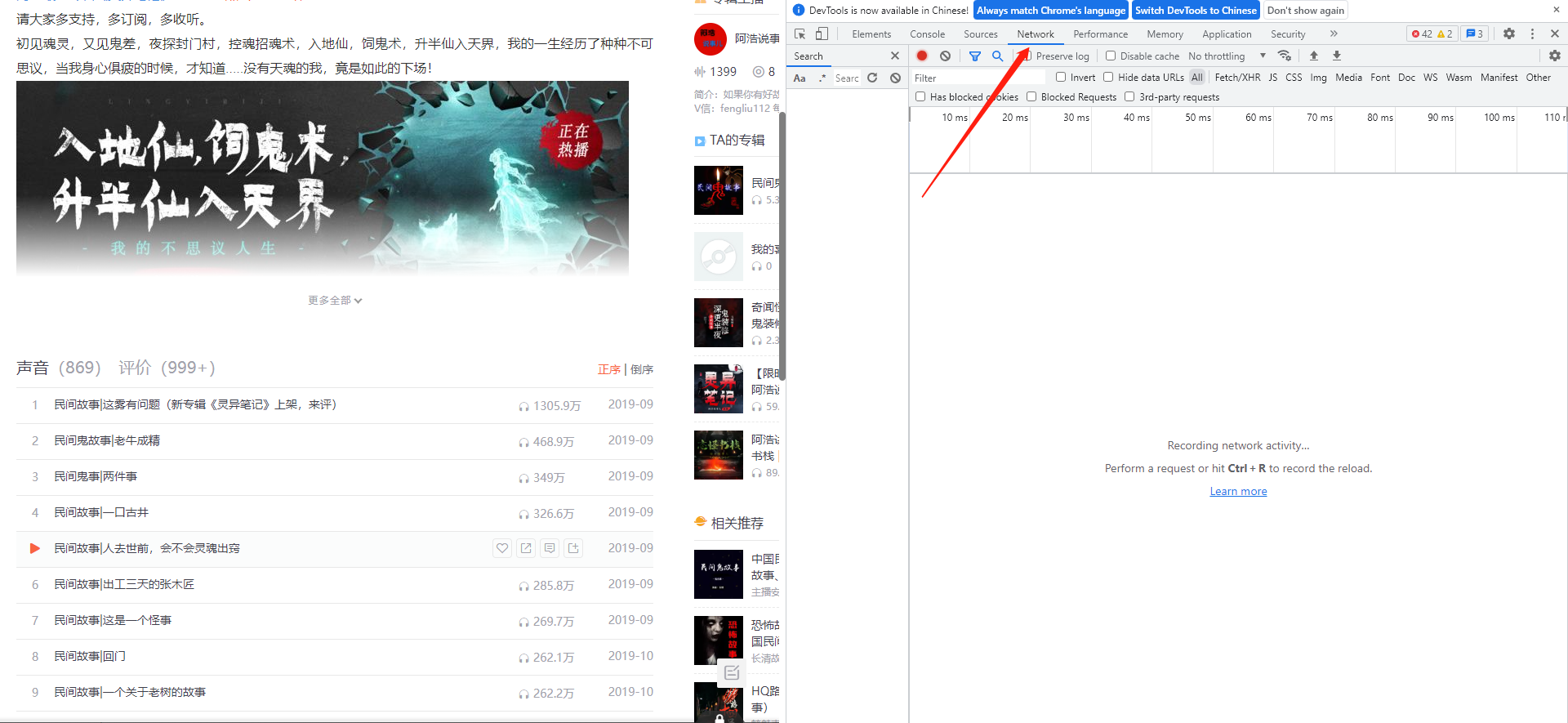
需求是要下载专辑中的音频,音频是属于媒体文件,所以点开Media
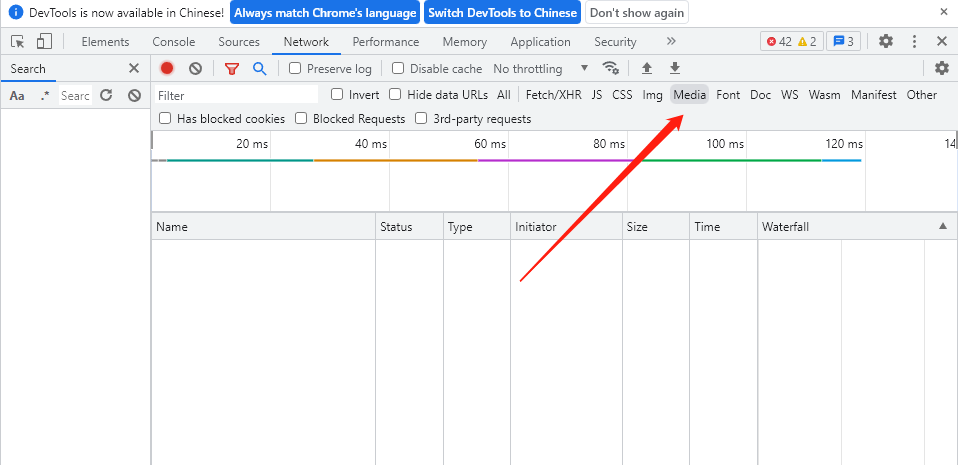
可以看到现在是什么都没有的状态,播放一个音频,可以发现已经抓取到了一个音频文件
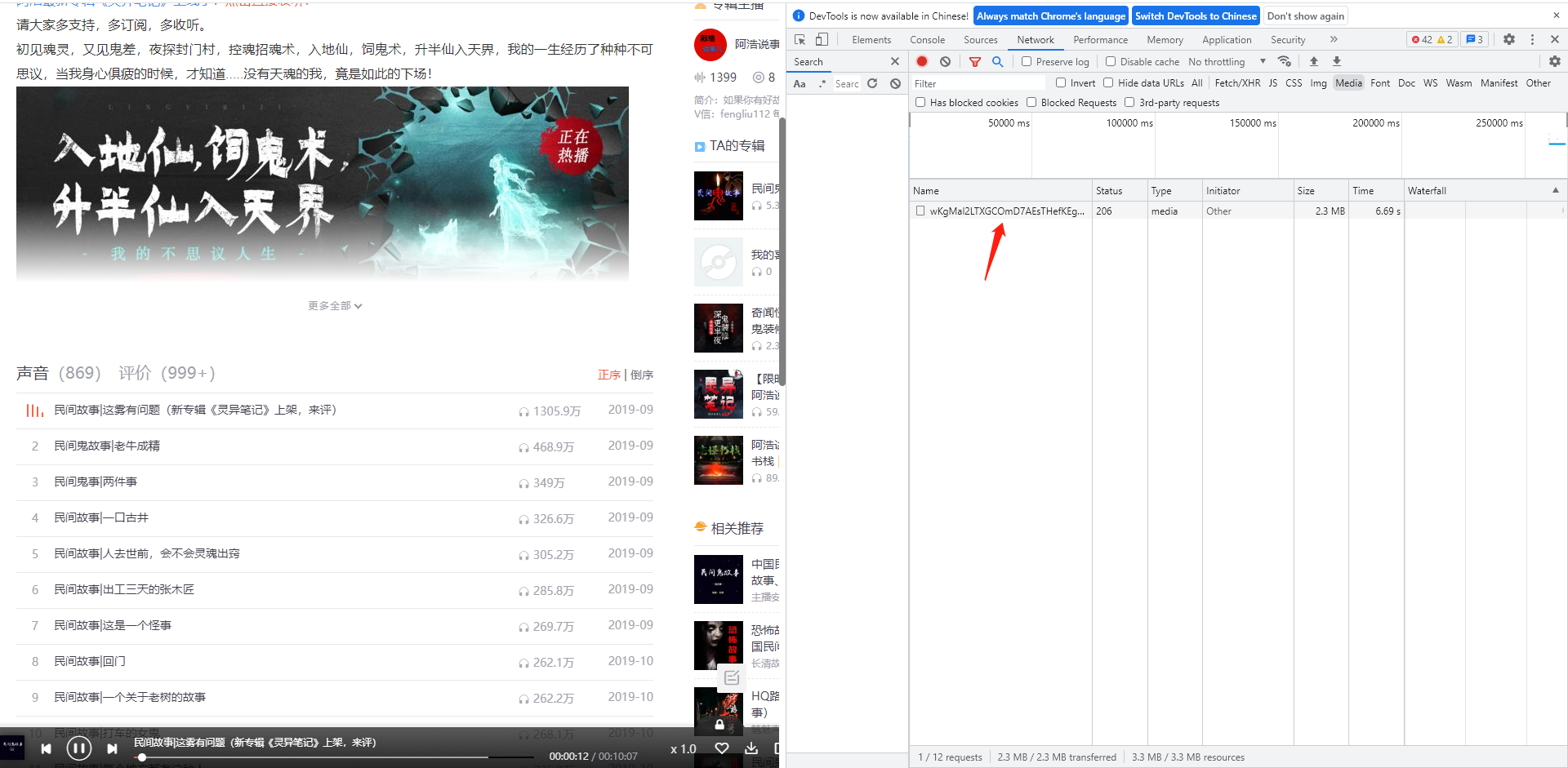
通过查看请求url可以看到这是一个m4a的音频文件
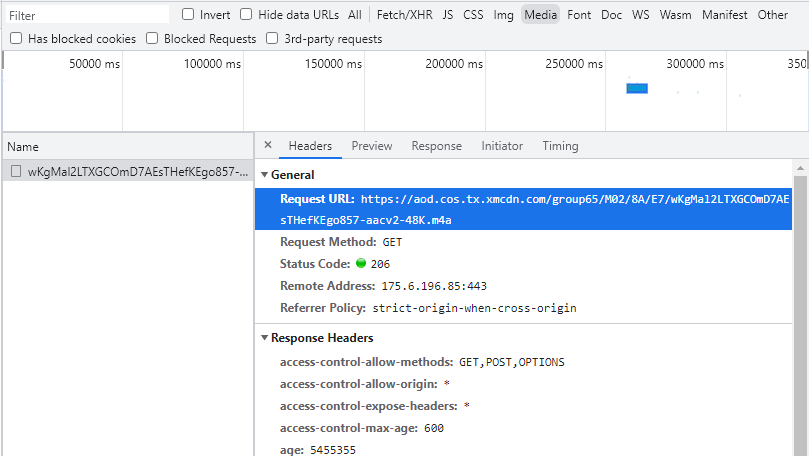
复制这个链接到另外一个窗口,可以知道这是一个音频链接,由于每个音频都是独一无二的,所以链接也必定是独一无二的,复制链接在开发者工具中搜索一下,可以发现这个链接是在一个链接请求中得到的
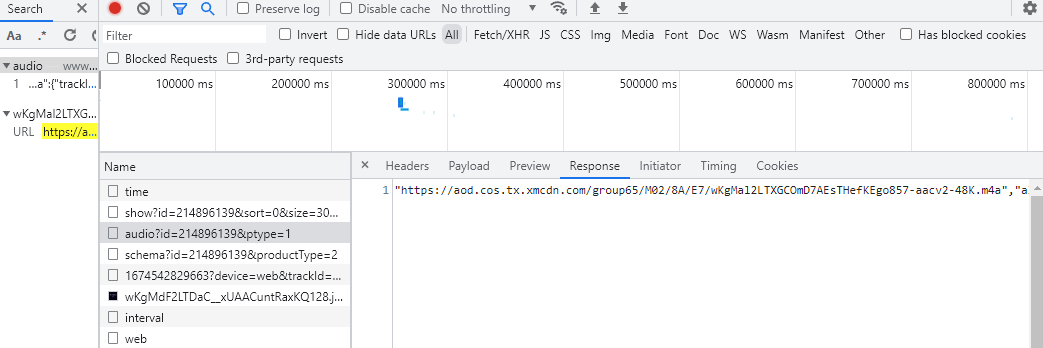
查看请求头
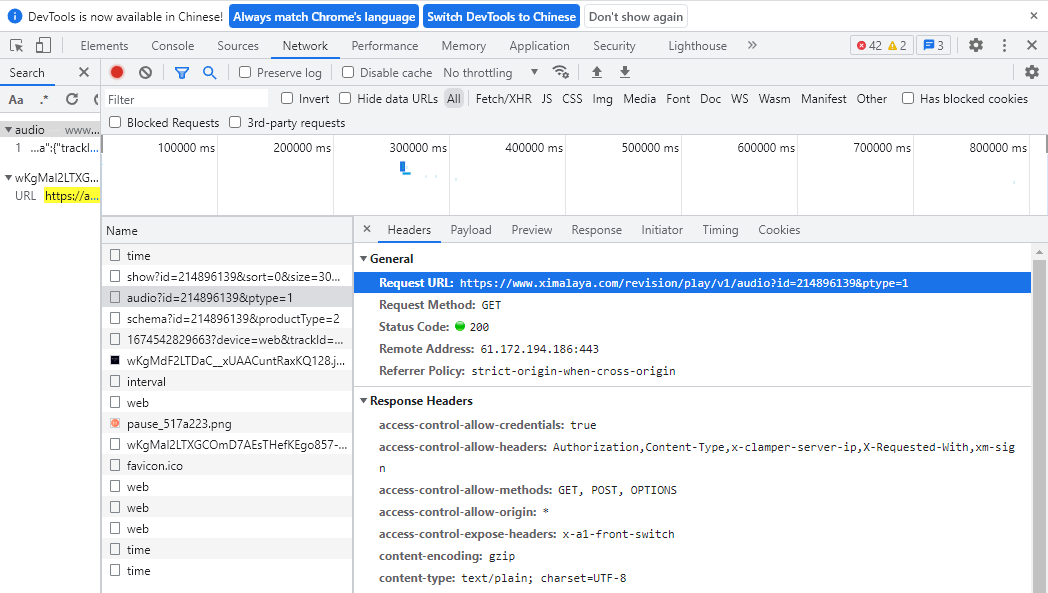
复制这个Request URL,写下以下代码
import requests
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=214896139&ptype=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
response = requests.get(url=url, headers=headers)
print(response.json())可以得到这样一个结果

访问字典中的元素,然后我们就得到这么一个链接
import requests
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=214896139&ptype=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
response = requests.get(url=url, headers=headers)
print(response.json()['data']['src'])
通过以下代码就可以下载文件
import requests
url = 'https://www.ximalaya.com/revision/play/v1/audio?id=214896139&ptype=1'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
response = requests.get(url=url, headers=headers)
audio_url = response.json()['data']['src']
audio_res = requests.get(audio_url, headers=headers)
audio_file = audio_res.content
with open('tmp.mp3', 'wb') as fp:
fp.write(audio_file)批量获取整个网页播放地址
在上一步已经获得了一个音频的请求地址:url = 'https://www.ximalaya.com/revision/play/v1/audio?id=214896139&ptype=1',可以知道这个音频id是214896139,所以需要去获取每个不同的id。
复制专辑首页的地址https://www.ximalaya.com/album/29535750, 通过开发者工具可以知道请求方式是get
然后完成一个请求,搜索音频id可以得到以下结果
import requests
url = 'https://www.ximalaya.com/album/29535750'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
res = requests.get(url, headers=headers)
html = res.text
print(html)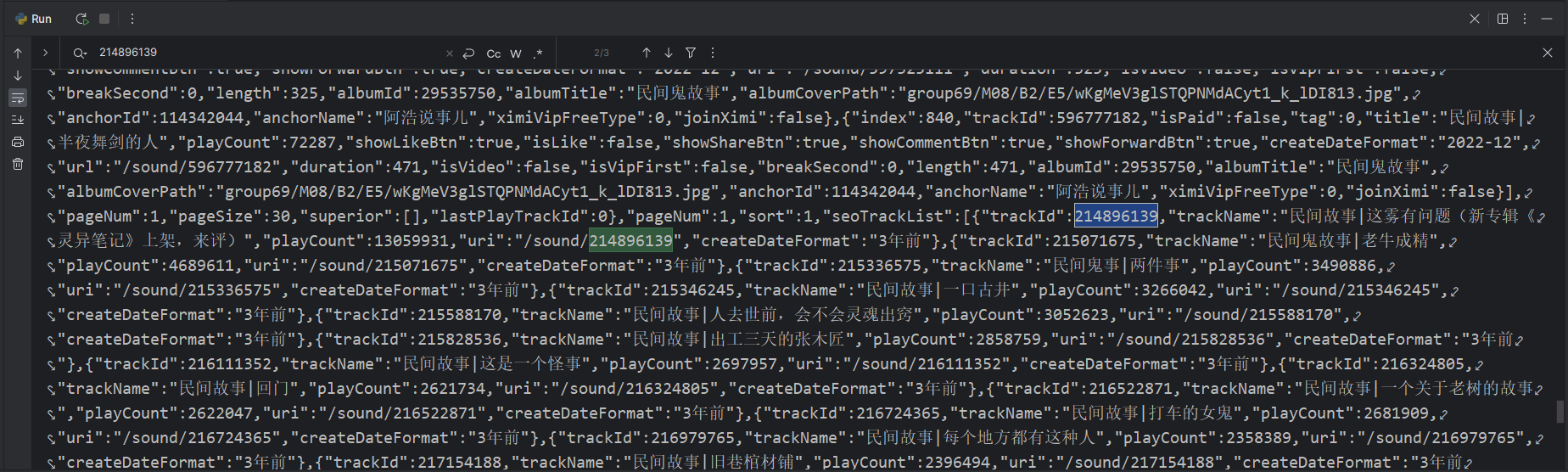
接着观察可以知道trackId是音频的id,trackName是音频的名字。然后我们通过一个简单的正则表达式获取这些数据
import requests
import re
url = 'https://www.ximalaya.com/album/29535750'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
res = requests.get(url, headers=headers)
html = res.text
audio_info = re.findall('"trackId":(\d+),"isPaid":false,"tag":0,"title":"(.*?)"', html)
trackIds = []
trackNames = []
for trackId, trackName in audio_info:
trackIds.append(trackId)
trackNames.append(trackName)
print(trackId, trackName)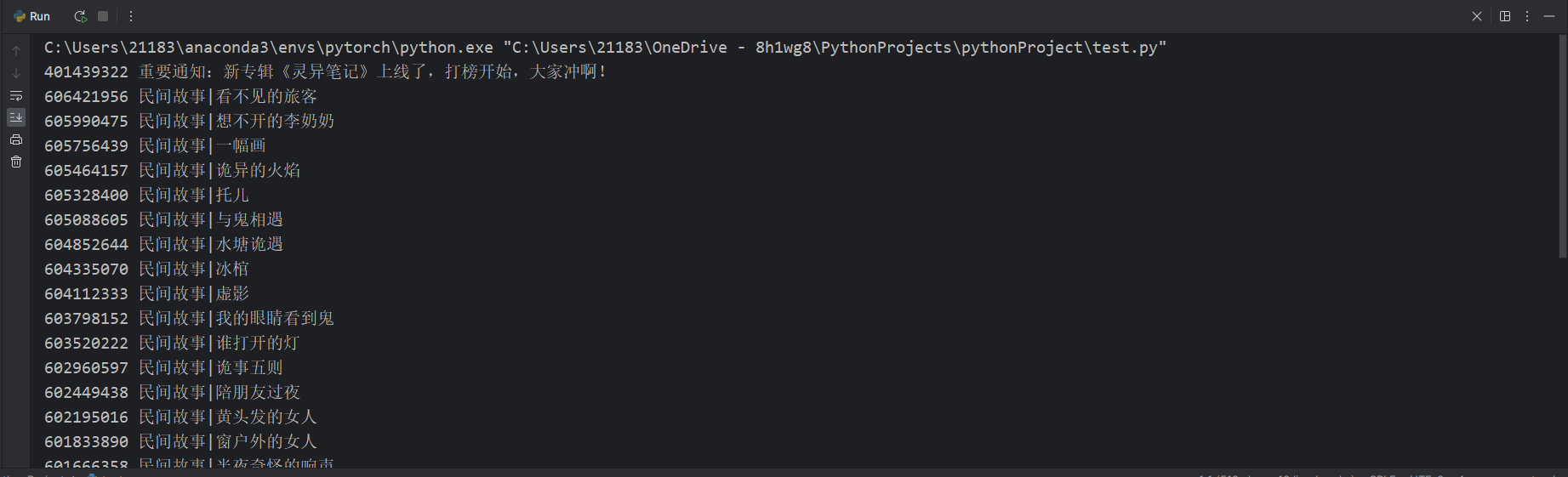
这样我们获取的id和文件名,但是这里只有30个,并不是总的内容
获取整个专辑地址
继续查看专辑页面,可以发现一页目录正好是30个,其他的需要翻页,那就通过抓包工具看看是发送了什么才首先翻页的
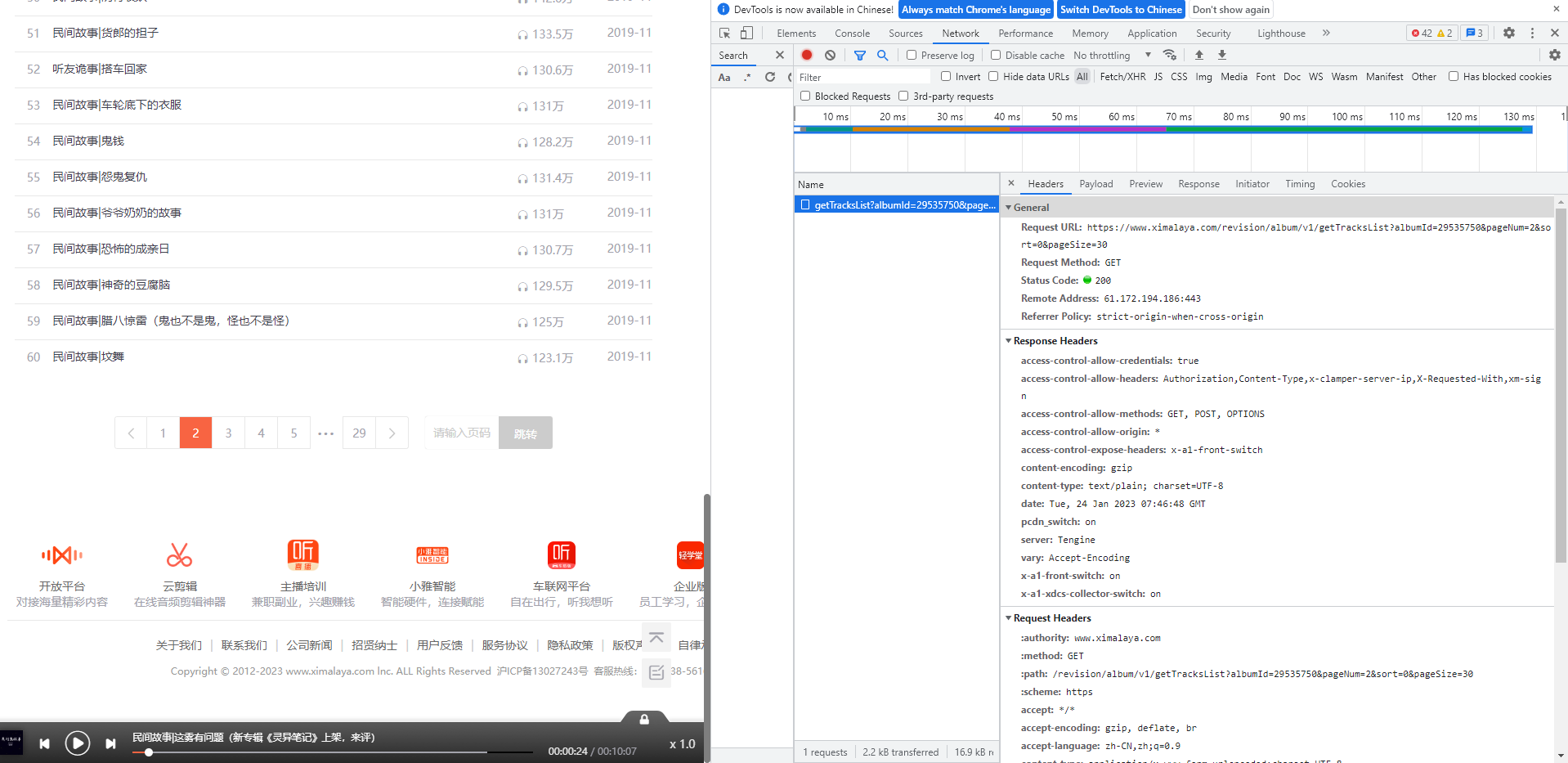
点击第二页可以发现是这个url=https://www.ximalaya.com/revision/album/v1/getTracksList?albumId=29535750&pageNum=2&sort=0&pageSize=30,请求方式是get,我们知道get请求是将要请求的数据放在url中,点开Payload,发现有以下对于关系
albumId: | 专辑编号 |
|---|---|
pageNum | 页码 |
sort | 正序还是逆序 |
pageSize | 一页中目录有多少 |
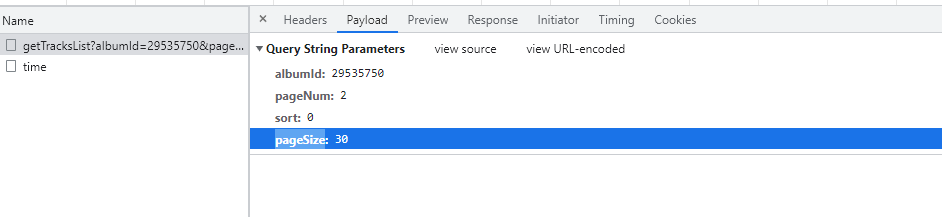
当然,这些东西可能不能一下就理解,由于get的请求在url中,你可以通过修改url中的参数查看来得到以上结果。
得到以上内容,我们就可以通过修改上面的参数来获取不同专辑,不同页码的目录了。
到这里,基本上就可以得到所有的专辑了,但是,我们不知道专辑中有多少页,所以不能完整的下载所有的音频,继续查看开发者工具中的Response
可以看到这个data里面有一个key为trackTotalCount的参数,正好是我们的总集数,我们就可以通过向上取整得到需要循环多少次。
import requests
import re
import math
import os
url = 'https://www.ximalaya.com/revision/album/v1/getTracksList?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
albumId = 29535750
params = {'albumId': albumId, 'pageNum': 1, 'sort': 0, 'pageSize': 30}
tmp_res = requests.get(url, headers=headers, params=params)
size = tmp_res.json()['data']['trackTotalCount']
max_page = math.ceil(size / 30)完整代码
整理一下可以得到以下完整代码
import requests
import re
import math
import os
url = 'https://www.ximalaya.com/revision/album/v1/getTracksList?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
albumId = input('请输入喜马拉雅小说的id号:\t')
params = {'albumId': albumId, 'pageNum': 1, 'sort': 0, 'pageSize': 30}
tmp_res = requests.get(url, headers=headers, params=params)
size = tmp_res.json()['data']['trackTotalCount']
max_page = math.ceil(size / 30)
title = (tmp_res.json()['data']['tracks'])[1]['albumTitle']
audio_url = []
names = []
x = ''
for i in title:
if i == ' ' or i == '|':
continue
x = x + i
title = x
if not os.path.exists(os.path.join(title)):
os.mkdir(title)
for i in range(1, max_page + 1):
params = {'albumId': albumId, 'pageNum': i, 'sort': 0, 'pageSize': 30}
res = requests.get(url, headers=headers, params=params)
html = res.text
audio_info = re.findall('"trackId":(\d+),"isPaid":false,"tag":0,"title":"(.*?)"', html)
for track_id, name in audio_info:
audio_url.append(f'https://www.ximalaya.com/revision/play/v1/audio?id={track_id}&ptype=1')
names.append(name)
count = 0
for i in audio_url:
res = requests.get(i, headers=headers)
music = requests.get(res.json()['data']['src'], headers=headers)
print(f'正在下载:\t{names[count]}')
content = music.content
if not str(names[count]).endswith('.mp3'):
x = names[count] + '.mp3'
else:
x = names[count]
with open(os.path.join(title, x), 'wb') as fp:
fp.write(content)
count = count + 1
评论区